Cubic (ASR) Documentation
Cubic is Cobalt’s automatic speech recognition (ASR) engine. It can be deployed on-prem and accessed over the network or on your local machine via an API. We currently support C++, C#, Go, Java and Python, and can add support for more languages as required.
Once running, Cubic’s API provides a method to which you can stream audio. This audio can either be from a microphone or a file. We recommend uncompressed WAV as the encoding, but support other formats such as MP3.
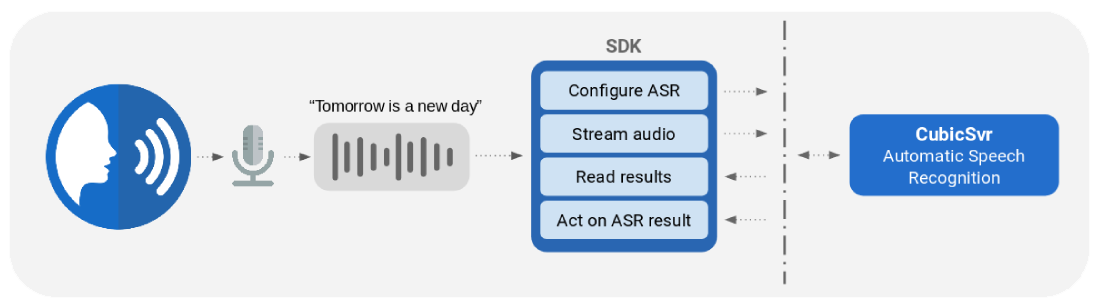
Cubic’s API provides a number of options for returning the speech recognition results. The results are passed back using Google’s protobuf library, allowing them to be handled natively by your application. Cubic can estimate its confidence in the transcription result at the word or utterance level, along with timestamps of the words. Confidence scores are in the range 0-1. Cubic’s output options are described below.
Automatic Transcription Results
The simplest result that Cubic returns is its best guess at the transcription of your audio. Cubic recognizes the audio you are streaming, listens for the end of each utterance, and returns the speech recognition result.
Cubic maintains its transcriptions in an N-best list, i.e. is the top N transcriptions from the recogniser. The best ASR result is the first entry in this list.
Click here to see an example json representation of Cubic’s N-best list with utterance-level confidence scores
{
"alternatives": [
{
"transcript": "TOMORROW IS A NEW DAY",
"confidence": 0.514
},
{
"transcript": "TOMORROW IS NEW DAY",
"confidence": 0.201
},
{
"transcript": "TOMORROW IS A <UNK> DAY",
"confidence": 0.105
},
{
"transcript": "TOMORROW IS ISN'T NEW DAY",
"confidence": 0.093
},
{
"transcript": "TOMORROW IS A YOUR DAY",
"confidence": 0.087
}
],
}
A single stream may consist of multiple utterances separated by silence. Cubic handles each utterance separately.
For longer utterances, it is often useful to see the partial speech recognition results while the audio is being streamed. For example, this allows you to see what the ASR system is predicting in real-time while someone is speaking. Cubic supports both partial and final ASR results.
Confusion Network
A Confusion Network is a form of speech recognition output that’s been turned into a compact graph representation of many possible transcriptions, as here:
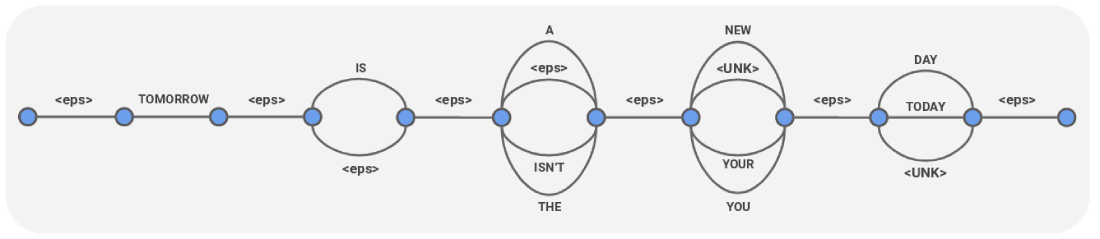
Note that <eps> in this representation is silence.
Click here to see an example json representation of this Confusion Network object, with time stamps and word-level confidence scores
{
"cnet": {
"links": [
{
"duration": "1.350s",
"arcs": [
{
"word": "<eps>",
"confidence": 1.0
}
],
"startTime": "0s"
},
{
"duration": "0.690s",
"arcs": [
{
"word": "TOMORROW",
"confidence": 1.0
}
],
"startTime": "1.350s"
},
{
"duration": "0.080s",
"arcs": [
{
"word": "<eps>",
"confidence": 1.0
}
],
"startTime": "2.040s"
},
{
"duration": "0.168s",
"arcs": [
{
"word": "IS",
"confidence": 0.892
},
{
"word": "<eps>",
"confidence": 0.108
}
],
"startTime": "2.120s"
},
{
"duration": "0.010s",
"arcs": [
{
"word": "<eps>",
"confidence": 1.0
}
],
"startTime": "2.288s"
},
{
"duration": "0.093s",
"arcs": [
{
"word": "A",
"confidence": 0.620
},
{
"word": "<eps>",
"confidence": 0.233
},
{
"word": "ISN'T",
"confidence": 0.108
},
{
"word": "THE",
"confidence": 0.039
}
],
"startTime": "2.298s"
},
{
"duration": "0.005s",
"arcs": [
{
"word": "<eps>",
"confidence": 1.0
}
],
"startTime": "2.391s"
},
{
"duration": "0.273s",
"arcs": [
{
"word": "NEW",
"confidence": 0.661
},
{
"word": "<UNK>",
"confidence": 0.129
},
{
"word": "YOUR",
"confidence": 0.107
},
{
"word": "YOU",
"confidence": 0.102
}
],
"startTime": "2.396s"
},
{
"duration": "0s",
"arcs": [
{
"word": "<eps>",
"confidence": 1.0
}
],
"startTime": "2.670s"
},
{
"duration": "0.420s",
"arcs": [
{
"word": "DAY",
"confidence": 0.954
},
{
"word": "TODAY",
"confidence": 0.044
},
{
"word": "<UNK>",
"confidence": 0.002
}
],
"startTime": "2.670s"
},
{
"duration": "0.270s",
"arcs": [
{
"word": "<eps>",
"confidence": 1.0
}
],
"startTime": "3.090s"
}
]
}
}
Formatted output
Speech recognition systems typically output the words that were spoken, with no formatting. For example, utterances with numbers in might return “twenty seven bridges”, and “the year two thousand and three”. Cubic has the option to enable basic formatting of speech recognition results:
- Capitalising the first letter of the utterance
- Numbers: “cobalt’s atomic number is twenty seven” -> “Cobalt’s atomic number is 27”
- Truecasing: “the iphone was launched in two thousand and seven” -> “The iPhone was launched in 2007”
- Ordinals: “summer solstice is twenty first june” -> “Summer solstice is 21st June”
Note that word level timestamps and confidences aren’t supported when formatting is enabled.
Obtaining Cubic
Cobalt will provide you with a package of Cubic that contains the engine, appropriate speech recognition models and a server application. This server exports Cubic’s functionality over the gRPC protocol. The https://github.com/cobaltspeech/sdk-cubic repository contains the SDK that you can use in your application to communicate with the Cubic server. This SDK is currently available for the Go and Python languages; and we would be happy to talk to you if you need support for other languages. Most of the core SDK is generated automatically using the gRPC tools, and Cobalt provides a top level package for more convenient API calls.